变脸 (2) --- 实现
次访问
总序
“换脸”Python实现共分为四个部分,第一部分是原理讲解,第二部分是Python实现,第三部分是效果改进,前三部分都是单张图片,第四部分是应用到视频。
网上的很多教程没有原理讲解,所以也许可以照猫画虎,但没有总体的理解,就很难有自己的改进方法,希望本四次的分享对你有帮助。
第二部分 Python3实现
在第一部分中,我们提到,换脸主要包括以下步骤:
1. 确定人脸位置
2. 把图乙的人脸大小和方向调节得和图甲中的差不多
3. 挖掉图甲中原来的人脸,换成图乙中的人脸
下面我们依次来实现。
准备
- Python包准备
我使用的是Ubuntu系统,Windows类似,用到的Python3 的主要有 $dlib$, $opencv$ 和$numpy$,请自行安装。 导入包代码如下:
1 | import sys, os |
文件夹
本项目的文件夹如下,face 是根目录,下面有个 changeFace.py ,写代码,与 changeFace.py 同级建两个文件夹,一个 model/ ,用来放模型,一个 faces/ ,用来放图片。
- face/
- changeFace.py
- model/
- faces/
- face/
dlib 训练结果下载
对于确定人脸的关键点,已经有训练好的模型,官网下载 shape_predictor_68_face_landmarks.dat 和 dlib_face_recognition_resnet_model_v1.dat 文件。放在上一步说的 model/ 文件夹下。
- 图片准备
随便找两张只有一个人的正脸的图片,图片大小可以不一样,最好一男一女,这样换脸后也比较明显。分别命名成 boy.jpeg 和 girl.jpeg。我们的目标给男孩子换上女孩的脸^-^。

使用dlib预测器
下面使用dlib预测器,做一些初始化。
1 | import sys, os, glob |
获取脸部关键点
1 | # 获取脸部关键点 |
运行 test_get_landmark(), 可以看见输出一些两列的矩阵,每行代表一个点。
人脸对齐
两张图片上的脸的大小和方向很可能是不同的,要换脸,那把脸变得差不多大是必须的。这个过程使用 Procrustes analysis(普氏分析),具体细节可以参考这里 。其实主要也是通过平移、旋转等仿射变化实现。代码如下:
1 | # 使用普氏分析调整脸部 |
下面具体利用上面的仿射变化函数 trans_mat 及图片大小,进行变化
1 | # 把 image 变成 dshape 大小,并用仿射矩阵 M 进行变化,这里的M就是上面的 trans_mat |
运行 test_wrap_image(), 效果如下:
![]()
多余的背景是我的桌面,上面是截图。最右面一张是变化后的效果,可以看其脸型大小和图片尺寸都和 boy 大小差不多了。
获取人脸掩模
先用 boy 的脸来做实验,其实脸主要看眼睛、鼻子和嘴巴的位置,我就要这几个关键部位。那先找出脸的形状,这个用 opencv 的凸包函数 convexHull() 来实现。
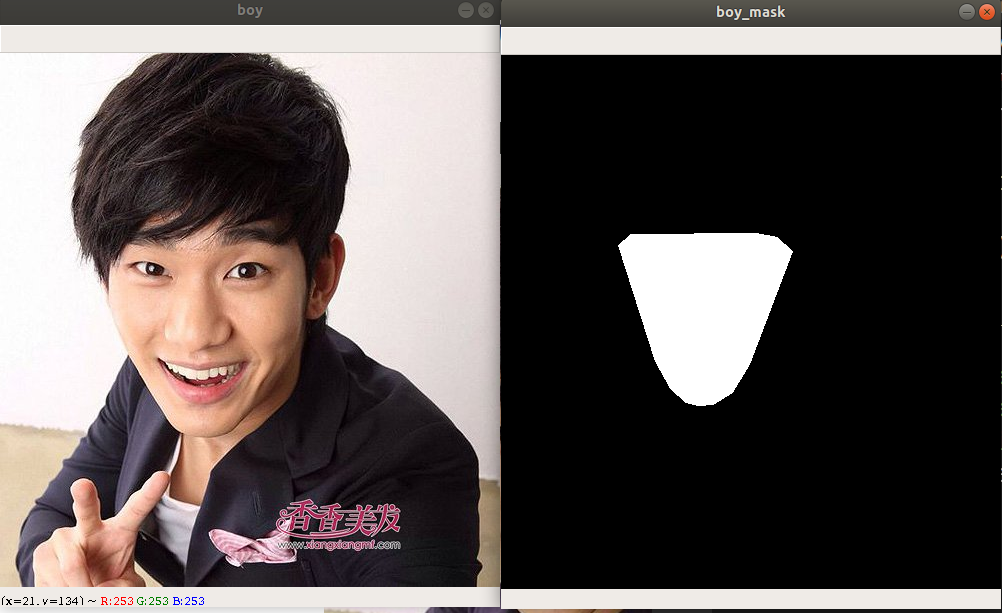
右图就是左图脸的掩模。代码实现如下:
1 | # 在img上绘制points点列表的凸包,Python参数默认引用,所以此处没用返回值 |
运行 test_get_face_mask(), 效果如上。
换脸
到上面,基本工作完成了,那就来看看怎么让 boy 有 girl 的脸。下面依次实现
- 把 girl 的脸变成和 boy 一样大小;
- 拿到 girl 的脸和 boy 去掉脸的剩下部分,这步用掩模辅助实现。其实这里只有一个掩模,因为两张脸认为一样大,这样两张脸可以无缝连接;
- 用矩阵加法和对应元素相乘的方法实现换脸,因为图片颜色为 0
255,这里要变成01。
下面是代码实现:
1 | def change_face(): |
运行 change_face(), 即可看见拭目以待的效果!如下,好看不?

从左到右依次为原始boy,调整脸和图片大小后的 girl,换脸后的boy(人妖)。
总结
以上就是换脸Python实现的全部内容了,可以看出换脸后及其不自然,下面一节来完善一下。汇总一下看到最终效果的代码。
1 | import sys, os, glob |